
Degradation-Aware Frequency-Separated Transformer for Blind Super-Resolution
Published in International Conference on Computational Visual Media, 2025
Hanli Zhao, Binhao Wang, Wanglong Lu*, Juncong Lin
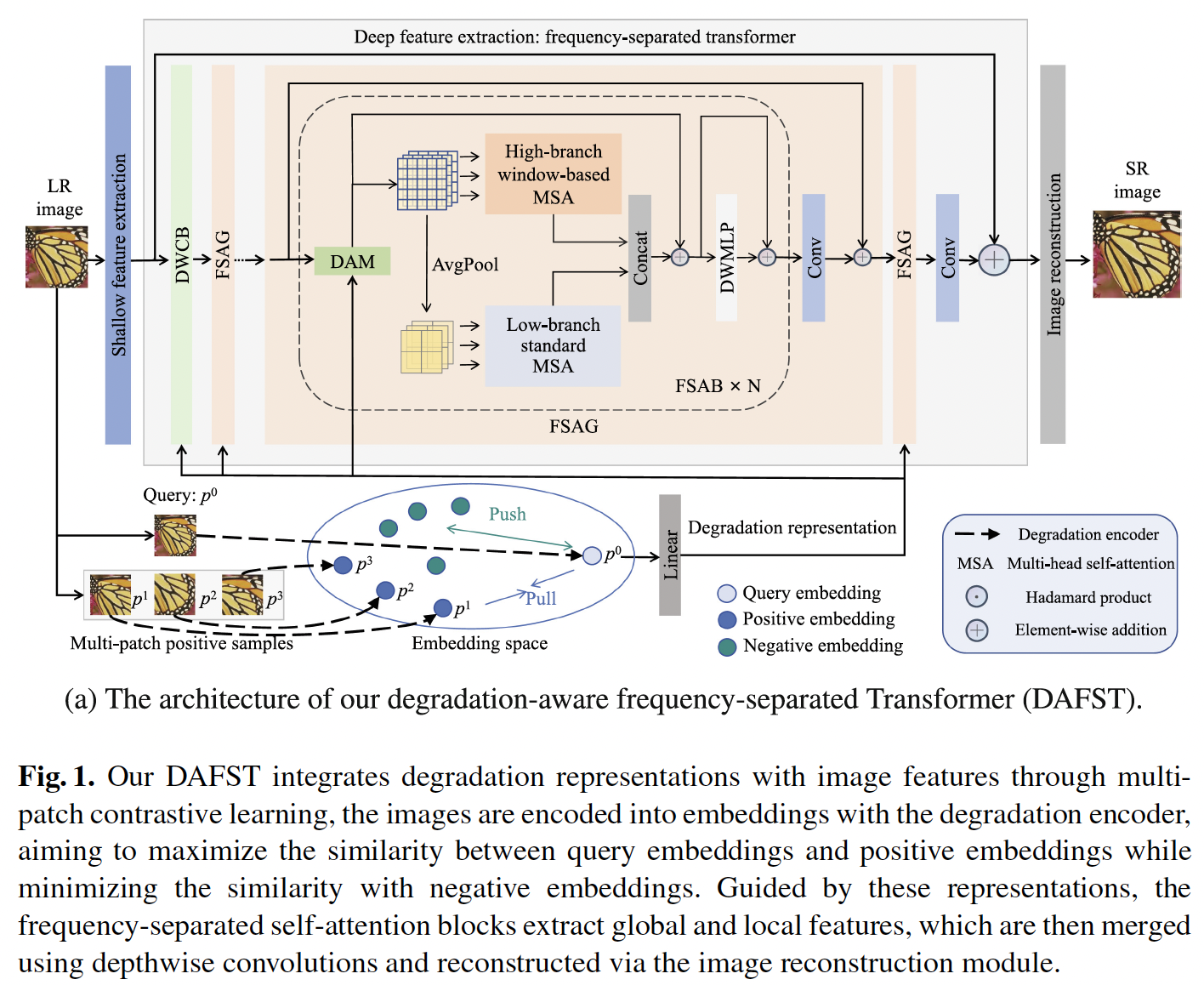 Brief description:
Brief description:
Blind image super-resolution involves reconstructing high-resolution images from low-resolution inputs with various unknown degradations. It is a challenging task due to the limited information available from the degraded images. While existing methods have achieved impressive results, they often overlook high-frequency or low-frequency features, reducing their effectiveness. To solve this problem, we propose a frequency-separated Transformer framework with degradation-aware learning for blind super-resolution. We first introduce a multi-patch contrastive learning approach to implicitly learn discriminative degradation representations. To fully utilize degradation representations as guidance information, a frequency-separated self-attention mechanism is introduced to extract global structural and local detail features separately. Our degradation-aware frequency-separated Transformer progressively restores high-quality images using successive frequency-separated self-attention blocks. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods on four benchmark blind super-resolution datasets, while also achieving lower GPU memory usage during training and faster inference speed.
Recommended citation:
@InProceedings{10.1007/978-981-96-5809-1_13,
author="Zhao, Hanli
and Wang, Binhao
and Lu, Wanglong
and Lin, Juncong",
editor="Didyk, Piotr
and Hou, Junhui",
title="Degradation-Aware Frequency-Separated Transformer for Blind Super-Resolution",
booktitle="Computational Visual Media",
year="2025",
publisher="Springer Nature Singapore",
address="Singapore",
pages="231--252",
abstract="Blind image super-resolution involves reconstructing high-resolution images from low-resolution inputs with various unknown degradations. It is a challenging task due to the limited information available from the degraded images. While existing methods have achieved impressive results, they often overlook high-frequency or low-frequency features, reducing their effectiveness. To solve this problem, we propose a frequency-separated Transformer framework with degradation-aware learning for blind super-resolution. We first introduce a multi-patch contrastive learning approach to implicitly learn discriminative degradation representations. To fully utilize degradation representations as guidance information, a frequency-separated self-attention mechanism is introduced to extract global structural and local detail features separately. Our degradation-aware frequency-separated Transformer progressively restores high-quality images using successive frequency-separated self-attention blocks. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods on four benchmark blind super-resolution datasets, while also achieving lower GPU memory usage during training and faster inference speed.",
isbn="978-981-96-5809-1"
}