
Visual style prompt learning using diffusion models for blind face restoration
Published in Pattern Recognition, 2025
Wanglong Lu, Jikai Wang, Tao Wang, Kaihao Zhang, Xianta Jiang, Hanli Zhao*
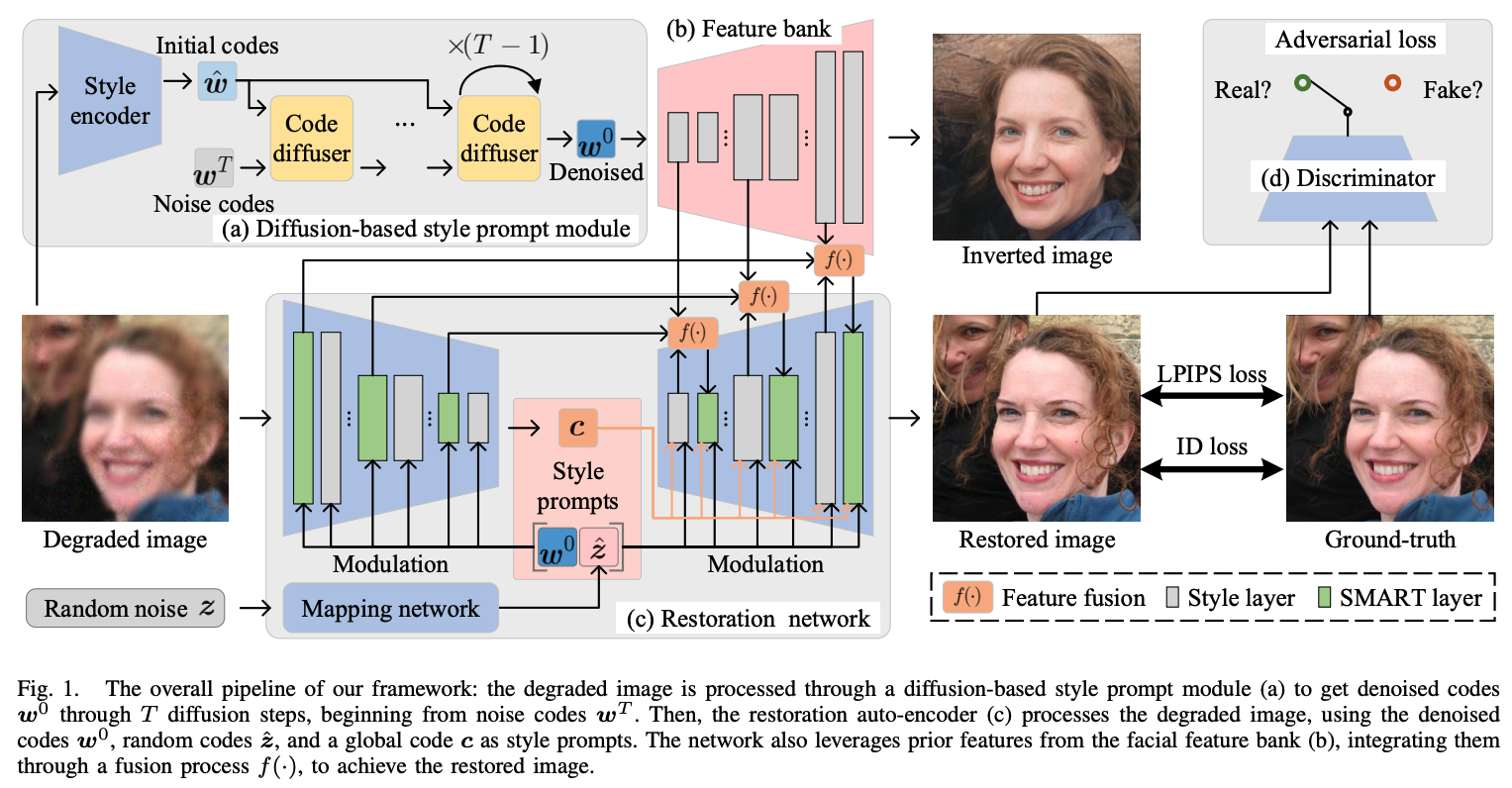 Brief description:
Brief description:
Blind face restoration aims to recover high-quality facial images from various unidentified sources of degradation, posing significant challenges due to the minimal information retrievable from the degraded images. Prior knowledge-based methods, leveraging geometric priors and facial features, have led to advancements in face restoration but often fall short of capturing fine details. To address this, we introduce a visual style prompt learning framework that utilizes diffusion probabilistic models to explicitly generate visual prompts within the latent space of pre-trained generative models. These prompts are designed to guide the restoration process. To fully utilize the visual prompts and enhance the extraction of informative and rich patterns, we introduce a style-modulated aggregation transformation layer. Extensive experiments and applications demonstrate the superiority of our method in achieving highquality blind face restoration.
Recommended citation:
@article{LU2025111312,
title = {Visual style prompt learning using diffusion models for blind face restoration},
journal = {Pattern Recognition},
volume = {161},
pages = {111312},
year = {2025},
issn = {0031-3203},
doi = {https://doi.org/10.1016/j.patcog.2024.111312},
url = {https://www.sciencedirect.com/science/article/pii/S003132032401063X},
author = {Wanglong Lu and Jikai Wang and Tao Wang and Kaihao Zhang and Xianta Jiang and Hanli Zhao},
keywords = {Denoising diffusion probabilistic models, Generative adversarial networks, Blind face restoration},
abstract = {Blind face restoration aims to recover high-quality facial images from various unidentified sources of degradation, posing significant challenges due to the minimal information retrievable from the degraded images. Prior knowledge-based methods, leveraging geometric priors and facial features, have led to advancements in face restoration but often fall short of capturing fine details. To address this, we introduce a visual style prompt learning framework that utilizes diffusion probabilistic models to explicitly generate visual prompts within the latent space of pre-trained generative models. These prompts are designed to guide the restoration process. To fully utilize the visual prompts and enhance the extraction of informative and rich patterns, we introduce a style-modulated aggregation transformation layer. Extensive experiments and applications demonstrate the superiority of our method in achieving high-quality blind face restoration.}
}